프로젝트명 : Kaggle Instacart 이커머스 데이터 분석
1. 활용 데이터
데이터 전처리(데이터 병합)
기존 데이터 1. products

기존 데이터 2. aisles

기존 데이터 3. departments
기존 데이터 4. order_products_prior
기존 데이터 5. orders

데이터병합 1. products_merged = products + aisles + departments

데이터병합 2. orders_products = orders + order_products_prior

최종 데이터. merged = orders_products + products_merged

데이터 병합 코드
orders_prior = orders[orders['eval_set'] == 'prior']
# 상품 정보 통합
products_merged = products.merge(aisles, on='aisle_id') \
.merge(departments, on='department_id')
# 주문 정보 통합
orders_products = order_products_prior.merge(orders, on='order_id')
# 상품 + 주문
merged = orders_products.merge(products_merged, on='product_id')
데이터 전처리(feature 생성)
1. 상품 정보(product_stats)
- reorder 지표 기준 선정 이유
- 재구매를 지표로 삼은 이유 및 재구매 지수 설명
- 사용자 행동 데이터를 통해 제품의 충성도, 지속 수요 가능성, 마케팅 우선순위를 판단하고자 함
- 한 번만 구매되고 다시는 구매되지 않는 제품보다, 재구매가 반복되는 제품이 더 가치 있음
- 재구매 지수를 통해 알 수 있는 것
- 재구매율(reorder_rate) : 해당 제품을 다시 산 비율
- 재구매 총수량 : 단순 누적 재구매 수 (볼륨 중심)
- 재구매 유저 수 : 반복적으로 산 유저가 몇 명인지 (확산성)
- 왜 reorder_score = reorder_rate * log1p(total_orders) 방식을 썼는지
- reorder_rate: 질적 요소 (해당 제품을 재구매한 비율 → 사용자 충성도 지표)
- log1p(total_orders): 양적 요소 (해당 제품의 구매량 규모)
- log를 사용한 이유는 너무 많은 주문 수의 영향력을 완만하게 조정하기 위해 (log 스케일링)
- 재구매율만 보면 소수에게 열광적인 제품이 상위에 뜨고, 주문량만 보면 대중적이나 반복 구매가 없는 제품이 상위에 뜸 → 두 요소를 균형 있게 반영하는 하이브리드 점수 필요
- 재구매를 지표로 삼은 이유 및 재구매 지수 설명
# 재구매율 계산
product_stats = merged.groupby('product_id').agg( # product_id기준 group화
total_orders=('order_id', 'count'), # 전체 주문량
reorders=('reordered', 'sum') # 재구매 주문량
).reset_index()
product_stats['reorder_rate'] = product_stats['reorders'] / product_stats['total_orders'] # 재구매율
product_stats['reorder_score'] = product_stats['reorder_rate'] * np.log1p(product_stats['total_orders'])
# 제품 정보 병합 (미리 만들어 놓은 products_merged 사용)
product_stats = product_stats.merge(products_merged[['product_id', 'aisle', 'department']], on='product_id', how='left')
product_stats 데이터

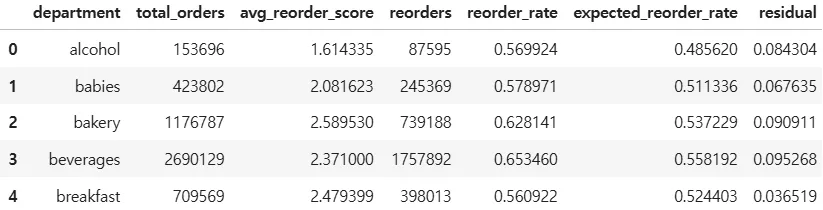
2. 부서별 요약(dept_summary)
- 생성 이유 : 4. 진열 구역(aisle/department) 기반 분석 도구
- 부서별 요약 데이터(dept_summary) : department기준 전체 주문량, 재구매 점수 평균, 재구매 주문량, 재구매율, 기대 구매 비율(회귀모델 학습), 잔차(reorder_rate - expected_reorder_rate)
3. Oragin여부 컬럼추가(is_organic)
- 생성 이유 : 유기농 경험 고객을 대상으로 재구매율/제품 다양성 기준 등급 나누기 위해
- 데이터 병합 최종 데이터인 merged에 is_organic 컬럼 추가
4. 유기농 경험 사용자 정보(organic_user_stats)
- 생성 이유 : . 프리미엄/Organic 집중 분석 도구
- 유기농 경험 사용자 정보(organic_user_stats) : user_id, 전체 유기농 주문량, 유기농 재주문량, 유기농 제품 다양성, 재주문 비율, 충성도 등급
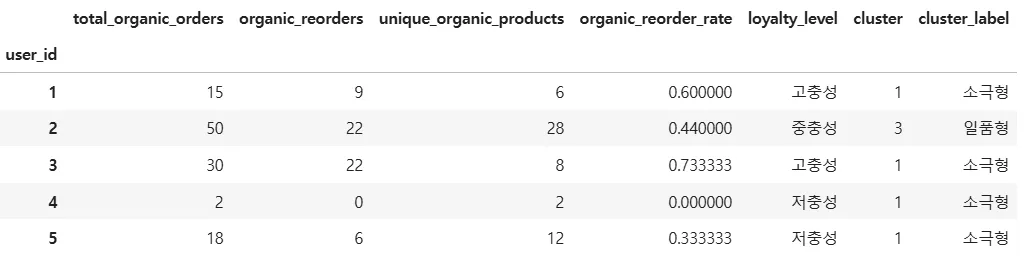
5. 상품별 주문 간격 정보(product_order_gap)
- 생성 이유 : 주기가 일정하고 재구매율 높은 상품 구독형 제안 분석 도구
- 상품별 주문 간격 정보(product_order_gap) : product_id, product_name, 평균 주문 간격, 주문간격 level(8일이하 Low, 8~12일 Mid, 12일 이상 High), 재주문율, 재주문 점수, 총 주문량, 부서

소주제 : 상품별 재구매율 분석
2 - (1) EDA
[목표] 상품별 재구매율을 분석하여 상위 15개의 상품들을 선정하고 해당 상품들을 중심으로 어떤 마케팅 전략을 제시
[데이터 전처리]
(1) products
- product 갯수 : 49,688개
- 한번도 판매되지 않은 상품 : 3개
- product_id : 3630, product_name : Protein Granola Apple Crisp, aisle_id : 57(granola), department_id : 14(breakfast)
- product_id : 7045, product_name : Unpeeled Apricot Halves in Heavy Syrup, aisle_id : 88(spreads), department_id : 13(pantry)
- product_id : 46625, product_name : Single Barrel Kentucky Straight Bourbon Whiskey, aisle_id : 31(refrigerated), department_id : 7(beverages)
(2) prior + train order
- 이전 구매목록들과 최종 구매목록을 합쳐 재구매율 확인하고자 함
- 1~2번만 판매된 상품의 경우 재구매율 분석으로 인사이트가 없으므로 제외하고자 함
- 1회 판매된 상품을 제외
- product 갯수 : 102개 제외
- 2회 판매된 상품 제외
- product 갯수 : 239개
- 상품이 딱 2번 팔린 경우, 가능한 재구매 패턴은 다음 2가지판매 횟수 재구매 수 재구매율 의미
즉, 0.0 또는 0.5 중 하나2 1 0.5 1명이 사고, 같은 사람이 또 삼 2 0 0.0 2명이 각각 1번씩 삼 (재구매 없음) - → 샘플 수가 너무 작아서 통계적으로 신뢰하기 어려움
- 3회 이상 판매된 상품
- product 갯수 : 49,344개
[데이터 전처리]
- product_name, department, aisle 병합
- Feature 생성
- total_orders = reordered + not_reordered
- reorder_rate = reordered / total_orders
- reorder_score = reorder_rate * log(total_orders)
- log 사용하는 이유
- total_orders는 편차가 크기 때문에 그대로 쓰면 매우 많이 팔린 상품이 지표를 지배
- log(total_orders)를 쓰면 비교적 덜 팔린 상품도 평가 대상이 될 수 있도록 스케일링
- 지표의 비중을 완만하게 조정 (exponential domination 방지)
- log 사용하는 이유
[EDA]
(1) 전체 주문 중 재구매 비율

- 과반수 이상이 재구매에 해당하므로 재구매는 분석대상으로 타당
- 피드백 : 단순히 과반수 이상이 재구매에 해당한다는 배경은 근거로 부족
- → 재주문을 지표로 삼는 이유를 좀 더 설득력 있게 만들 필요가 있음
(2) 평가지표를 통한 상위 15개 제품 선정


- 평가지표 실험
- reorder_score = reorder_rate × log(total_orders)
- 재구매율이 높은데 판매량도 많은 상품에 높은 점수 부여
- 평가지표를 통해 마케팅/추천용으로 "우선순위 높은 제품" 선정에 유용
- Organic제품과 Non-Organic제품 색 구분(재구매 점수가 높은 제품들 중 상당수가 Organic에 해당)
- [x] department missing 제품들 중 Organic 제품 비율
- [x] 재주문 점수 상위 상품들 중 Organic 제품 비율
- department와 aisle로 구분했을 때 건강식품·신선식품 카테고리에서 높은 재구매율을 보이는 경향이 확인되었음
- Top 15개의 department
- produce (8)
- dairy eggs (5)
- beverages (2)
- Top 15개의 aisle
- fresh fruits (6)
- milk (3)
- packaged vegetables fruits (2)
- water seltzer sparkling water (2)
- cream (2)
- Top 15개의 department
(3) Organic 비율 비교
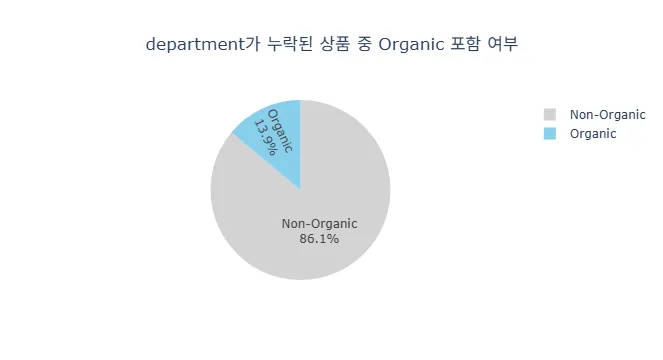
- 전체 상품 중 Organic 포함 비율은 10.1%로 크지 않지만 재주문 점수 상위 100개 상품 중 Organic 포함 비율은 54%로 별도의 상품군으로 관리 필요
- 현재 department나 aisle로 구분되어 있지 않으며, department가 missing 제품들 중 13.9%가 Organic 상품들로 확인


(4) 카테고리별 추천 리스트 생성
- 카테고리별 재구매율이 높은 Top 10 추천 리스트 생성
- reorder_rate는 재구매 충성도
- total_orders는 인기/신뢰도
- 두 변수를 0~1로 정규화한 후 가중합하여 score 계산
- MinMax 정규화 + 가중합 점수(scored_df['rate_norm'] * 0.7 + scored_df['order_norm'] * 0.3)
(5) Department Missing 분류된 Products 문제 검토
- products : 49,688개
- 구매된 적이 없는 3개 상품은 missing 아님
- order products : 49,685개
- missing products : 1,255개
- missing 중 Organic products : 175개
- missing 중 Non-Organic products : 1,080개
- orders (order_id 기준으로 하나씩)
- 전체 order 수[orders] : 3,421,083회
- prior order : 3,214,874회
- trian order : 131,209회
- prior + trian order 수 : 3,346,083회
- test order 수 : 75,000회
- df_all (order_products_prior + order_products_train) : 33,819,106회 ( order_id별, product_id 별로 각 행으로 잡힘 )
- order_products_prior : 32,434,489회
- order_products_train : 1,384,617회
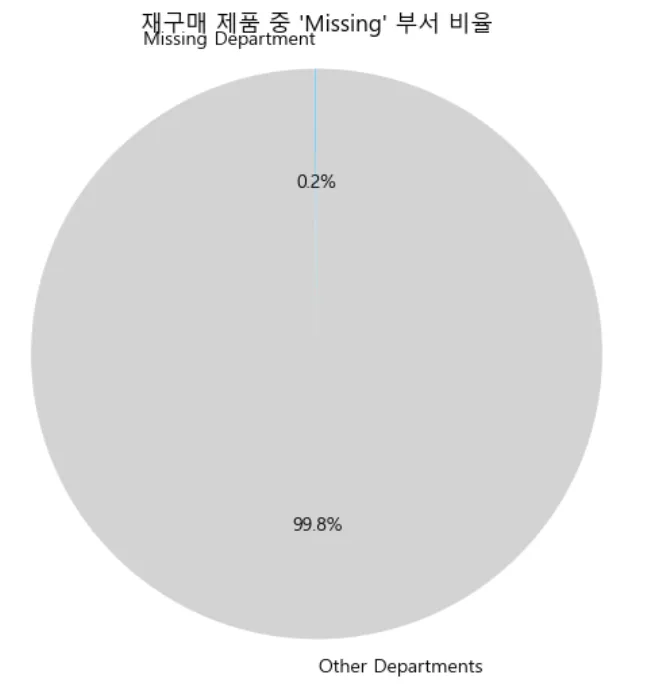
- reorder 수 [ reordered == 1 ] : 19,955,360회
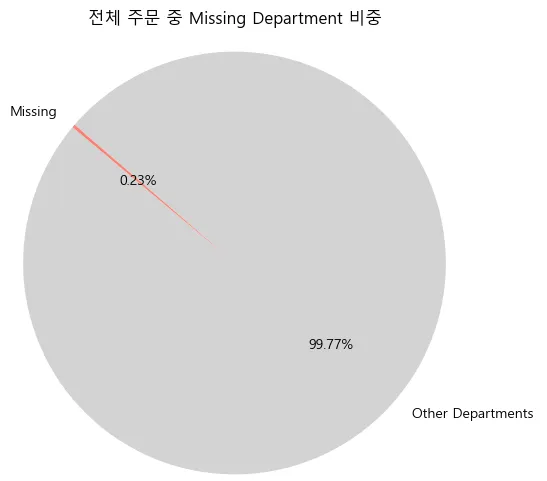
- missing_reorders : 30,519회(전체 reorder 중 0.2%, 1,255개 상품) ⇒ 재구매율을 분석하는데 있어서는 missing 분류는 큰 영향은 없음
- 전체 주문 중 missing department 비중 0.23% 큰 영향 없음
- (해당 전체 주문은 재주문율 분석을 위해 3회 이상 필터링 됨)
(6) 재구매 점수 Top 15 상품들을 재구매한 사용자 분석

- 목표 : 충성도 및 제품 만족도 분석
- 재구매 점수 Top 15 상품들 중 10개이상 구매한 사용자가 145명으로 확인됨 → heavy_users로 분류하고 해당 사용자들이 구매하는 상품쌍(2개 조합)을 확인
- 과일 2가지, 또는 과일 + 우유인 경우가 대부분이었음(재구매는 주로 오래 보관하지 못하는 상품들, 아침식사 용도 위주로 이루어질 가능성 있음)

- heavy_users 기준 상품쌍(3개 조합) 확인(여전히 신선식품 3조합이 가장 많음)
- 같은 시기에 일정한 간격으로 구매되는지를 확인하여 구독 상품 출시
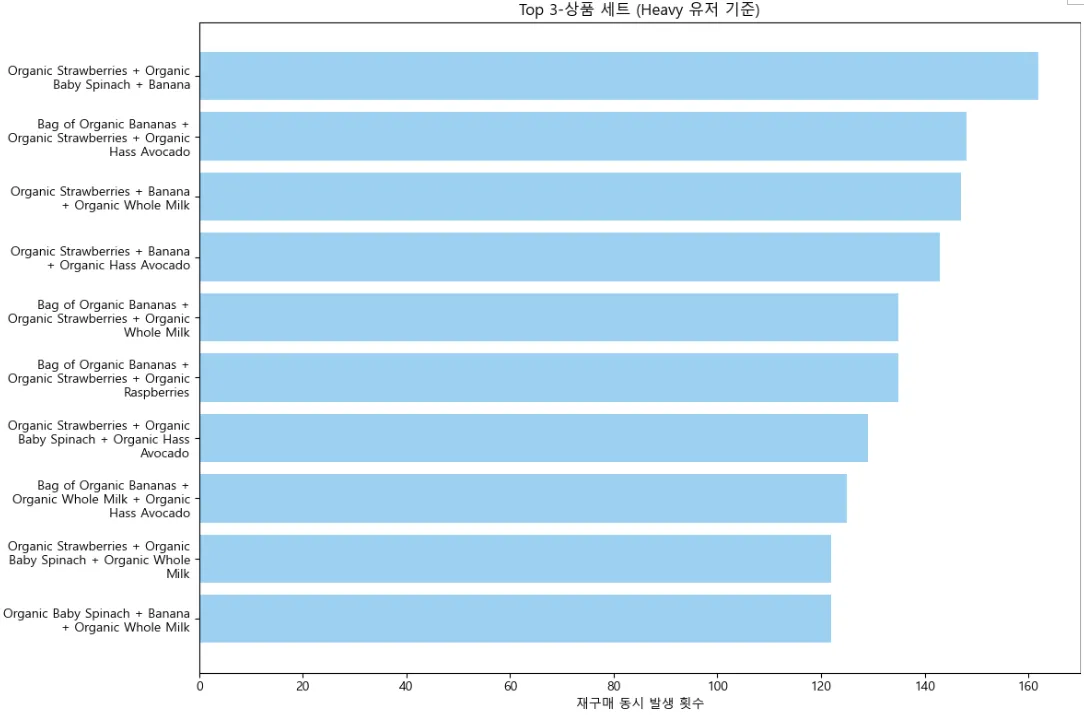
2 - (2) 데이터 분석 및 인사이트 도출
- 평가지표(reorder_rate * log(total_order))를 통해 “재구매 점수가 높은 제품 15개”를 선정하여 개별 상품을 마케팅 타겟 및 추천용으로 제시
- 평가지표 기준 우선순위 높은 제품 15개 중 11개가 Organic 제품 → Organic 집중 분석
- 해당하는 department는 produce(7개), dairy eggs(4개)
- Organic 제품군 별도 관리(사용자 패턴 분석 후 Organic 선호하는 사용자를 별도의 세그먼트로 분류하여 마케팅 또는 구독 서비스 홍보 가능)
- 카테고리별 재구매율이 높은 Top 10 추천 리스트 자동 생성
- 카테고리 선택시 재구매율이 높은 Top 10이 먼저 뜨도록하며, 이 때 Top1 ~ 3은 별도 표시
- 사용자별 재구매 패턴 분석 후 상품별 재구매율이 높은 상품과 사용자별 재구매율이 높은 상품의 교집합을 결합하여 묶음 상품 전략 제시(묶음 상품으로 레시피 제안이 가능하다면 마케팅 전략시 해당 레시피와 함께 안내 ex. 바나나 + 우유 + 아보카도 = 아보카도바나나 스무디)
소주제 : 사용자별 재구매율 분석
3 - (1) EDA
[목표]
- 사용자별 상위 재구매 품목 추출 → 고객 세그먼트 생성 (ex. 과일 자주 구매 고객 / 간편식 중심 고객) → 세그먼트별 마케팅 전략 수립
- 상품별 재구매율 상위 Top N과 사용자별 자주 구매한 상품 Top N의 교집합 도출하여 묶음 상품 제시
- 사용자별 재구매 품목 패턴을 분석하여 첫 구매자들에게 다음 상품을 제시하는 전략
[데이터 전처리]
- 사용한 데이터셋 : orders, order_products_prior, order_products_train
- Instacart eval_set별 사용자 분포 핵심 요약구분 prior train test
내용 마지막 주문 전까지의 모든 주문 마지막 주문 (+재구매 라벨 있음) 마지막 주문 (+라벨 없음) 포함된 user_id train과 test에 있는 user 모두 포함 train 전용 유저만 포함 test 전용 유저만 포함 order_products 있음? O O ❌ reordered 값? O O ❌ 목적 feature 생성용 학습용 예측 대상 - 데이터 병합 : order의 user_id를 order_products__prior, order_products_train에 붙이기
- 사용자 분포 확인
- 전체 사용자 수 : 206,209명
- 재구매 0회 사용자 수 : 1900명
- 재구매 1회 이상 사용자 수 : 204,309명
- 사용자별 재구매율을 확인하기 위해 사용자-상품별 재구매 수에서 재구매 = 0인 경우 제외하고 집계
- 사용자별 전체 구매수 & 재구매수 집계
- 사용자별 재구매율 계산
- 사용자-상품별 누적 재구매수 상위 25% 분위수 기준 재구매 횟수 4회
- 해당 횟수를 중심으로 사용자별 상위 재구매 품목 추출
3 - (2) 데이터 분석 및 인사이트 도출
- 사용자별로 전체 재구매 상품을 groupby하여 가장 많이 속한 department를 찾아 고객 세그먼트 분류
- 사용자-상품별 누적 재구매수 상위 25% 분위수 기준 재구매 횟수 4회 이상 재구매 품목만 필터링

- 사용자별로 가장 많이 재구매한 부서를 바탕으로 부서별 대표 상품을 자동 추천
- user_top_department : 각 사용자별 가장 많이 재구매한 department_id
- user_product_reorder_stats_filtered : 4회 이상 재구매된 상품 필터링된 상태 (user_id, product_id, reordered)
- products : 상품 메타데이터 (product_id, product_name, department_id, aisle 등)


- 마우스 커서를 올리면 해당 부서별 대표 상품 top 5가 뜨도록 treemap 재구성
- 상위 90% 부서만 남기고, 나머지는 '기타'로 합산

4. 최종 인사이트
[목표]
- 묶음 상품 전략
- 상위 재구매율 품목을 레시피 단위로 묶음화
- 예: 아보카도 바나나 스무디 세트
- 구성: 바나나 + 우유 + 아보카도
- 특이사항: 세 가지 모두 재구매율 상위 품목
- 콘텐츠 마케팅과 연계
- 제품 상세페이지 또는 알림톡/이메일에 레시피 콘텐츠 제공
- 영상/카드뉴스/인스타그램 등과 연계해 자연스러운 전환 유도
- 카테고리별 Top 10 추천 리스트 자동 생성
- 재구매 이력이 없는 사용자에게는 카테고리별 Top 10 추천 리스트 자동 생성
- 재구매 이력이 있는 사용자에게는 해당 사용자의 카테고리별 추천 리스트 Top n 생성 후 10 미만일 경우 추가적인 리스트는 위 카테고리별 Top 10에서 상위 (10-n)개 리스트 자동 생성
추가로 해볼 것
- 상품쌍 조합 확인하여 번들 기획
- Organic / department 고객세그먼트 나눴을때 각각 파트별 고객 충성도 파악해보기(충성도에 따라 다른 마케팅 필요, 할인/리마인드 등)
- 연관분석(Association, 장바구니 분석) : 상품이나 카탈로그의 배열, 교차판매, 판촉행사 등을 위한 목적으로 분석하는 방법
- products에 departments, aisles 이름 병합해서 departments별/ aisles 별 크기(종류) 확인하기
- orders에 주문시기를 넣어서 각 요일별/시간대별 가장 많이 팔리는 department 또는 aisle 찾아서 시간대별 마케팅 전략
- 시간대별 해당품목 한정수량 할인
- 요일별 해당품목 한정수량 할인
- 고객 세그먼트 분류 → 세그먼트별 대표 제품, 마케팅 전략 제시
- 구매 성향 기반
- 재구매율 기반 세그먼트 : 재구매율 높은 유저, 낮은 유저
- 총 주문 수 또는 활동 기간 기준 : 신규 유저 / 장기 이용자
- 정해진 카테고리 집중 유저 : 특정 department 구매 비중 70% 이상 → 편식형 유저
- 구매 주기 (구매 간격) 기반 : 매주 정기 주문 유저 vs 필요할 때만 주문하는 유저
- 상품 다양성 기반
- 구매한 상품 수가 많은 유저 vs 소수 품목만 반복하는 유저
- department 다양성 (entropy) 기반 분류
- brand 다양성이 높거나 낮은 유저
- 시간 기반 세그먼트
- 주로 언제 주문하는가 (요일, 시간대 등)
- 주말형 유저 vs 평일형
- 아침형 vs 야행성
- 구매 간격 : 평균, 표준편차
- 주로 언제 주문하는가 (요일, 시간대 등)
- RFM 세그먼트 (Recency, Frequency, Monetary)
- 라이프스타일 / 테마 기반
- Organic 제품 구매 비중이 높은 유저
- 베이비푸드, 반려동물, 글루텐프리 등 특정 테마 위주 유저
- 신선식품 중심 vs 저장식품 중심
- 군집 기반 (Clustering 기반 Segmentation)
- 위 모든 feature들을 벡터화해서 KMeans, DBSCAN 등 클러스터링으로 군집화
- 구매 성향 기반
- 현재 우리팀에서 분석해보지 않은 방향에 대해 고민해보기
<<4Ls 회고법>>
1. Liked 좋았던 것 : 학교를 다닐 때도, 직장에서 일을 하면서도 해보지 못한 프로젝트를 경험한 것
2. Lacked 아쉬웠던 것 : 지난 2주간 어떤 날은 새벽까지도 하고 주말 평일 가리지 않고 열심히 했으나, 생각보다 결과가 도출 되지 않았던 것.
3. Learned 배운 것 : 다양한 방면으로 분석 결과가 나오면서 괜찮다고 생각했으나 배경이나 설정 지표들에 대한 설득력이 많이 부족함을 깨달았음
4. Longed for 앞으로 바라는 것 : 결과가 좋지 않다고해서 낙담에 빠져있지 말고 얼른 또 열심히 배워나갈 것. 지치지 말 것.
'[패스트캠퍼스] 데이터분석 부트캠프' 카테고리의 다른 글
| [8주차 학습일지] 패스트캠퍼스 박두진 강사님 SQL 기초 정보 (1) (7) | 2025.08.13 |
|---|---|
| [7주차 학습일지] 패스트캠퍼스 파이썬 프로젝트 중간점검2 (11) | 2025.08.07 |
| [5주차 학습일지] 패스트캠퍼스 김인섭 강사님 머신러닝 특강 (3) | 2025.07.25 |
| [4주차 학습일지] 패스트캠퍼스 김인섭 강사님 파이썬 크롤링 (7) | 2025.07.18 |
| [3주차 학습일지] 패스트캠퍼스 김상모 강사님 파이썬 기초 문법 (탐색반) (2) | 2025.07.11 |



