[ 데이터 수집에 필요한 라이브러리 설치 ]
%pip install webdriver-manager selenium
from webdriver_manager.chrome import ChromeDriverManager
ChromeDriverManager().install()
# 크롬드라이버를 알아서 다운 받아주도록 하는 것from selenium import webdriver
# 드라이버를 통해서 Chrome 브라우저 실행
browser = webdriver.Chrome() # 계속 가져가야할 실행문
browser.get("https://www.naver.com")
# 위의 webdriver로 브라우저 실행하지 않으면 커넥팅이 안됨
[순서]
1. 데이터 수집을 위한 환경 구축
2. 데이터 수집 → 기본적인 수집에 대한 원리, 방법
from selenium.webdriver.common.by import By
# 주요 By 메서드
By.CLASS_NAME # 클래스명으로 요소 찾기
By.ID # ID로 요소 찾기
By.XPATH # XPATH로 요소 찾기
By.TAG_NAME # 태그 이름으로 요소 찾기(1) 네이버 뉴스 수집
url = 'https://search.naver.com/search.naver?ssc=tab.news.all&where=news&sm=tab_jum&query=%EB%8D%B0%EC%9D%B4%ED%84%B0+%EB%B6%84%EC%84%9D%EA%B0%80'
# 얻고자 하는 정보가 있는 페이지 url
browser.get(url)
1. 뉴스 제목 불러오기
from selenium.webdriver.common.by import By # By는 한번만 불러오면
browser.find_element(By.CLASS_NAME, 'BAeT2rSB_v3C8l_Lu2U6').text
# 텍스트 형태로 바꿔줄 것
# 보통의 요소들은 CLASS_NAME을 가지고 있으므로 위와 같이 불러오게 될 것
# 원래 CLASS_NAME은 'OqRuWgaJW9JVSHu5Dl92 BAeT2rSB_v3C8l_Lu2U6' 인데 크롤링 방지를 위해
# CLASS NAME이 공백을 포함할 수 있음 이럴 때는 공백을 기준으로 각각 넣어보기
결과 : '우송대 AI‧빅데이터학과 유학생 ‘영어 경제 에세이’ 수상'
목록들 중 맨 첫번째 뉴스 제목을 불러옴

2. 신문사 불러오기
browser.find_element(By.CLASS_NAME, 'HovnHEoPU37osdURhOMl').text
# 원래 CLASS NAME : OqRuWgaJW9JVSHu5Dl92 HovnHEoPU37osdURhOMl
# 신문사를 불러옴결과 : '뉴스1'
3. 기사 날짜 불러오기
browser.find_element(By.CLASS_NAME, 'WVEw9RqihlHJAhw04YDi').text
# 원래 CLASS NAME : sds-comps-base-layout sds-comps-inline-layout WVEw9RqihlHJAhw04YDi결과 : '2일전'
4. 요약 내용 불러오기
browser.find_element(By.CLASS_NAME, 'TajF3tviPufdG569L8jV').text
# 원래 CLASS NAME : OqRuWgaJW9JVSHu5Dl92 TajF3tviPufdG569L8jV결과 : '사물인터넷, 인공지능과 같은 최첨단 응용기술 관련 과정을 교육한다. 졸업 후 대기업·금융권의 소프트웨어 개발부서, 데이터 분석부서, 외국계 IT기업, 국내기업의 해외지사 전산부서의 소프트웨어 개발자, 정보보안(사이버보안) 전문가, 데이터베이스 관리자, 빅 등으로 활동하게 된다.'
5. 신문사와 날짜를 함께 불러오기
browser.find_element(By.CLASS_NAME, 'hxidan41VfRTvLNKvWQE').text.split('\n')[0:2]
# '\n'을 기준으로 구분 후 신문사와 날짜만 추출
# 원래 CLASS NAME : sds-comps-horizontal-layout sds-comps-full-layout sds-comps-profile type-basic size-lg title-color-g10 hxidan41VfRTvLNKvWQE
~ 지금까지 한 작업은 싱글 데이터 수집
6. 목록 전체 불러오기
data = browser.find_elements(By.CLASS_NAME, 'BAeT2rSB_v3C8l_Lu2U6')
# element에 s 붙으면 리스트로 됨
# elements는 리스트기 때문에 .text가 안됨
for i in data:
print(i.text)
7. 신문사명, 날짜, 제목, 요약 내용을 데이터 프레임에 넣어서 엑셀 또는 csv로 저장하기
# 1페이지의 전체 뉴스 데이터를 수집하시오.
# (1) 컨테이너를 찾는다 => 컨테이너의 클래스 명 파악
# (2) csv 형태로 데이터를 저장 => pandas
# browser.find_element(By.CLASS_NAME, 'SoaBEf').text
containers = browser.find_elements(By.CLASS_NAME, 'G4iVzGtaRpoFqUVVp1bP')
data = []
for index, i in enumerate(containers):
if index == 3: # 0, 1, 2 → 총 3개만 수집
break
# 계속해서 수집 시 오류 발생하여 3개까지만 수집
print(f'{index+1} 번째 데이터 수집 중입니다')
제목 = i.find_element(By.CLASS_NAME, 'BAeT2rSB_v3C8l_Lu2U6').text
언론사 = i.find_element(By.CLASS_NAME, 'HovnHEoPU37osdURhOMl').text
작성일 = i.find_element(By.CLASS_NAME, 'WVEw9RqihlHJAhw04YDi').text
내용 = i.find_element(By.CLASS_NAME, 'TajF3tviPufdG569L8jV').text
링크 = i.find_element(By.CLASS_NAME, 'TajF3tviPufdG569L8jV').get_attribute('href')
data.append({
'제목' : 제목,
'언론사' : 언론사,
'작성일' : 작성일,
'내용' : 내용,
'링크' : 링크,
}) # 리스트에 데이터를 담아주는 것
# titles = browser.find_elements(By.CLASS_NAME, 'n0jPhd')
# for i in titles:
# print(i.text)
# element에 elements를 붙이면 CLASS_NAME이 'n0jPhd'인 것들을 전부 긁어오도록 하는 것
# 여기에 바로 text를 붙이는 건 불가능
data결과:

import pandas as pd
df = pd.DataFrame(data)
# 데이터프레임으로 변환하여 csv로 저장
df.to_csv('네이버_뉴스_데이터분석가.csv', encoding='utf-8-sig')결과: 폴더 내에 csv 파일 확인 가능
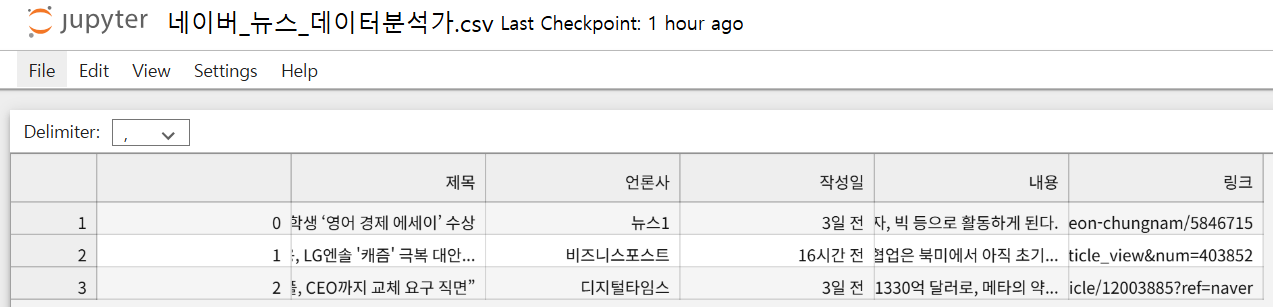
# 인덱스 없이 CSV 저장하려면 index = False로 저장
df.to_csv('네이버_뉴스_데이터분석가.csv', index=False, encoding='utf-8-sig')결과: index열 제거 후 다시 저장

4주차 소감
<<4Ls 회고법>>
1. Liked 좋았던 것 : 처음 들을 때는 정말 모르겠다가도 두 번 세 번 강의를 듣다보니 익숙해지는 것들이 생기는 것
2. Lacked 아쉬웠던 것 : 크롤링 및 파이썬을 이용한 시각화 자료 만들기에 어려움을 느끼고 강의 복습을 제대로 하지 못한 것
3. Learned 배운 것 : 크롤링 및 파이썬 시각화 자료 만들기, 다양한 자료로 미니 프로젝트를 진행하는 온라인 강의 다수 수강
4. Longed for 앞으로 바라는 것 : 집중도를 높이고 시간 배분을 좀 더 효율적으로 해서 다음주 파이썬 프로젝트 준비하기
'[패스트캠퍼스] 데이터분석 부트캠프' 카테고리의 다른 글
| [6주차 학습일지] 패스트캠퍼스 파이썬 프로젝트 중간점검 (11) | 2025.08.01 |
|---|---|
| [5주차 학습일지] 패스트캠퍼스 김인섭 강사님 머신러닝 특강 (3) | 2025.07.25 |
| [3주차 학습일지] 패스트캠퍼스 김상모 강사님 파이썬 기초 문법 (탐색반) (2) | 2025.07.11 |
| [2주차 학습일지] 이동훈 강사님 엑셀 및 기초 수학/통계 시작하기 요약 (1) | 2025.07.02 |
| [특강일지] 수료생에게 직접 들려듣는 패스트캠퍼스 부트캠프 활용 방법 (1) | 2025.07.01 |



